the0 v1.3.2 - State and Queries
In-depth look at how we implemented state management and query capabilities across 7 SDKs in both Docker and Kubernetes environments.
January 16, 2025
In the last version, we finally broke up with the master-worker model. No tears, no regrets—it was holding us back. This wasn't just spring cleaning; it was a full architectural reset that cleared the path for proper state management and query capabilities.
So, what are state and queries in the context of the0? In this blog post, we'll explore the motivations behind this change, the implementation details, and the benefits it brings to developers using the0. For the full documentation, check out the state and queries guides.
Motivation
So when I was grinding away developing algorithmic trading bots for my startup quantitative research firm alphaneuron, I noticed a glaring hole in our setup. We had execution down pat—we could definitely implement strategies, deploy them, and let them rip. But there were two key pieces missing, leaving a gap in our capabilities.
State Management: Most of the bots in the0 prior to v1.3.2 were stateless, meaning they didn't maintain any internal state between executions. We were trusting external systems to store stateful information like positions, PnL, and historical data. This was fine for simple strategies since you can gather quite a bit of information from the exchange APIs such as positions, balances, trade history, orders, etc. However, more complex strategies require stateful behavior, such as tracking moving averages, tracking performance metrics for risk management purposes (e.g., Kelly Criterion requires knowledge of past wins/losses), or implementing more complex multi-leg execution strategies that require knowledge of prior actions taken by the bot. State management is crucial for these strategies to function correctly and efficiently.
Query Capabilities: In addition to state management, we also wanted to provide developers with the ability to query their bots for any relevant information they might need to know. Queries in this context refer not only to state but also other relevant information about the bot's behavior. For example, a developer might want to query the bot for its current position size, assets held, PnL, or even historical performance metrics. By providing developers an interface to implement queries, we let them gain insights into their bots' behavior and make informed decisions about their trading strategies. Queries can also be used to give developer on-demand calculations based on the bot's state and historical data, such as calculating risk metrics or performance indicators. Queries can use the bot's state and other 3rd party data to provide developers with valuable insights into their bots' behavior. Think of queries like HTTP endpoints that you can define on your bot that return relevant information when called. There were many times I wanted to know how risky my current position was based on the current market conditions and my bot's historical performance. With query capabilities, I could easily implement a query that calculates and returns this information on demand.
Implementation
Building this tested every assumption I had. Why, you ask?
- There are a dozen ways to solve this. How do we plan to store state?
- We have 7 SDKs to support (Python, JS/TS, Rust, C#, C++, Scala, Haskell). How do we make sure all SDKs have consistent interfaces and capabilities?
- Bots run in isolated container environments (Docker/Kubernetes). How do we make state and queries work seamlessly across both environments?
- Bots can be realtime or scheduled. How do we handle queries for bots that aren't always running?
- State sync and query handling shouldn't interfere with the bot's main execution or add significant overhead. How do we ensure this?
- Every bot has different domain logic. How do we provide a flexible framework that lets developers define their own state structures and query endpoints?
That was a mouthful. But after a lot of thinking, designing, iterating, and maybe a little crying, we came up with a solution that actually works. So crack a cold one, sit back, and let's dive into the implementation details of state and queries in the0 v1.3.2.
Architecture Shift
Right off the bat, we had to pivot hard. In 1.2.0, we ghosted the master-worker model, which honestly made our lives a hell of a lot easier in 1.3.2. Now we have a unified runtime. In Docker mode, every bot runs as an isolated container. In Kubernetes mode, every bot runs as a pod. (For the full runtime architecture breakdown, see the runtime docs.) But before starting work on state and queries, we needed to address the giant, steaming elephants in the room.
- Where will we be handling state storage?
- Where will we be handling queries?
At first glance, it might seem logical to handle it in the things controlling the bot's lifecycle. In Docker's case that would be in the bot-runner and bot-scheduler for realtime and scheduled bots respectively, and in Kubernetes case that would be in the bot-controller and bot-scheduler for realtime and scheduled bots respectively. However, this approach has several drawbacks.
- Those components are primarily responsible for managing the bot's lifecycle and not cross-cutting concerns like state and queries. Adding state and query handling to these components would increase their complexity and make them harder to maintain. Literally, these components should only be concerned with starting, stopping, and monitoring bots. I wasn't about to violate single responsibility here.
- These components are mission-critical and adding state and query handling could introduce performance bottlenecks especially at scale. Think about it: starting goroutines to handle state persistence and query handling for potentially thousands of bots. This could lead to resource contention and degrade the overall performance of the system. We can't have these components being bogged down by state and query handling. Honestly, these components should be as lightweight as possible to ensure they can handle the load of managing a large number of bots efficiently.
- State and query handling are fundamentally different from each other and from bot lifecycle management. State management involves persisting and retrieving data, while query handling involves processing requests and returning results. Mixing these concerns in the same components would lead to a convoluted architecture that is hard to reason about.
- State and queries only apply when the bot is running. If we handle state and queries in the bot lifecycle components, we would need to implement additional logic to ensure that state and query handling only occurs when the bot is active. This adds unnecessary complexity to these components. Trust me bro, these components are already complex enough as is, and this is after we removed the master-worker model.
These and a slew of other reasons I can't be bothered to type out made it clear that we needed to handle state and queries within the bot itself. This way, we can ensure that state and query handling is tightly coupled with the bot's execution context, allowing for more efficient and effective management of these concerns. We already had a cross-cutting concern being handled in those components—logging—and honestly, that was a nightmare to maintain.
Enter the Daemon
So how do we handle state? Oh, and by state, I just don't mean variables, I mean ANY arbitrary form of data. It could be a simple integer or maybe a pickled sklearn model or any odd file you want to store. We don't want to limit developers to just data structures. If a developer wants to store a whole SQLite database as state, they should be able to do that. If they want to store a trained ML model as state, they should be able to do that too. State is ANY arbitrary data the developer wants to store. It's a concept not a specific data structure or storage format. Given this, we need to understand the locality of state. State is local to the bot. Each bot has its own state that is independent of other bots. This means that we need to handle state storage and retrieval within the bot's execution context. NOT in some external component managing the bot's lifecycle.
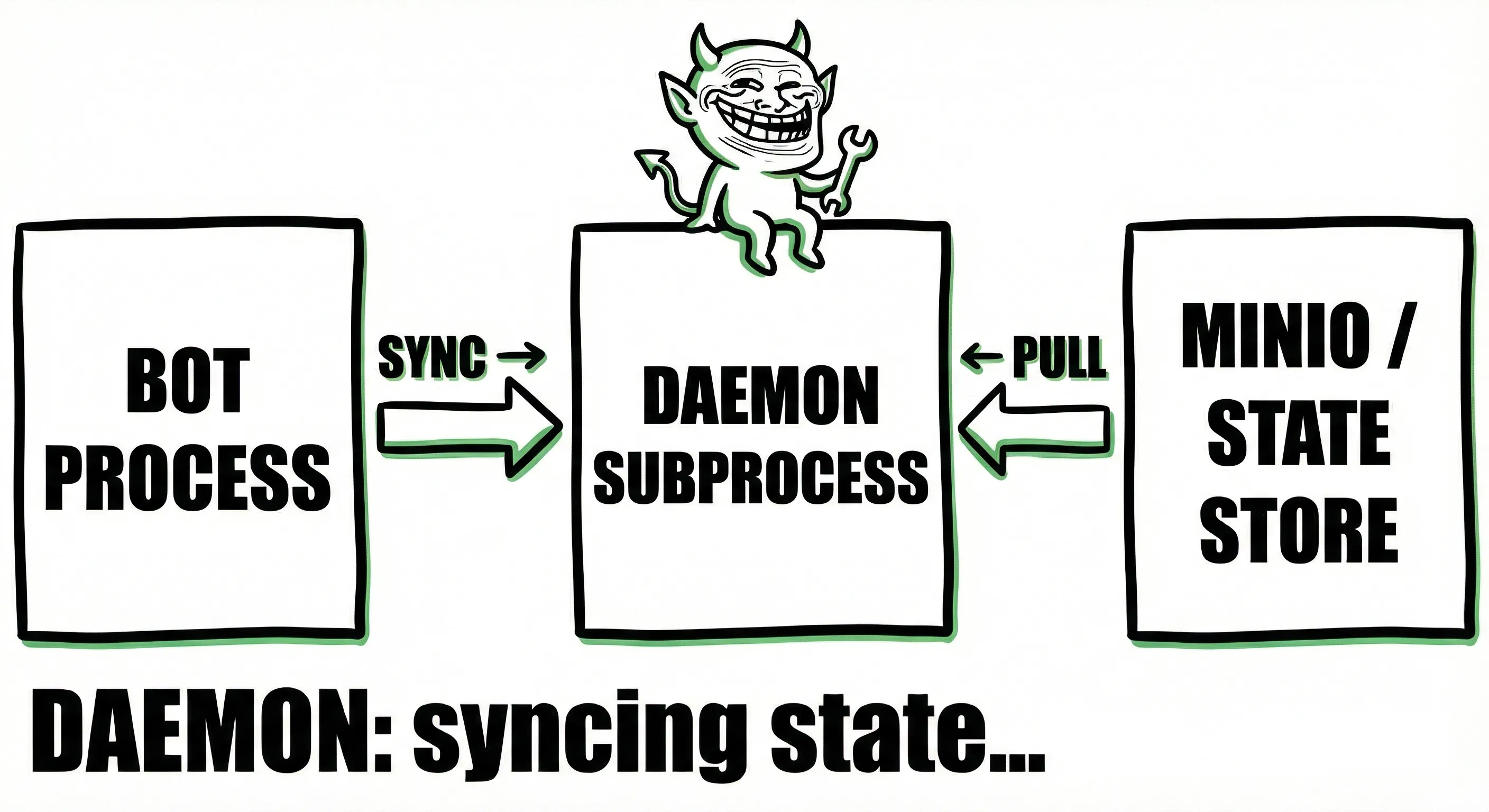
To achieve this we added a daemon process that runs alongside the bot's main execution thread. This daemon is responsible for synchronizing state with an object store (minio). The daemon runs in the background and periodically persists the bot's state to the object store. This way, the bot can maintain its state across executions and restarts without relying on external systems. On Docker, it looks like this:
The daemon uses fsnotify to watch for changes in the state directory. Whenever a change is detected, the daemon computes a hash of the state directory and compares it to the previous hash. If the hash has changed, it means that the state has been modified, and the daemon uploads the new state to MinIO.
This way, we ensure that only modified state is uploaded, reducing unnecessary data transfer and improving performance. On bot startup, the runtime execute command downloads the bot code and state from MinIO before starting the bot process. This ensures that the bot always starts with the latest state.
This solution was so clean I almost kissed my monitor. We effectively refactored logging to use the same daemon process. Now both state and logs are handled by the same daemon process, simplifying the architecture and reducing code duplication.
If you think about it, many companies implement a similar architecture:
- Datadog agent running on each host to collect logs and metrics
- Prometheus node exporter running on each host to collect system metrics
- Kubernetes kubelet running on each node to manage pods and containers
By extension, in K8s land we can effectively do the same thing with a bit more elegance using sidecar containers. But the core concept remains the same. Each bot (container/pod) has its own daemon process that handles state and log synchronization. K8s land looks like this:
This way, we maintain the same architecture across both Docker and Kubernetes modes, ensuring consistency and ease of maintenance. Now we can handle not only state but other cross-cutting concerns in the same way in the future if needed. Things like metrics and telemetry come to mind. Maybe in the future, when I'm not running on caffeine and hatred, we can add those too lol. For more details on how to use state in your bots, check out the state documentation.
Query Handling
Now queries were a bit more tricky (see the queries documentation for the developer-facing API). Queries need to be handled in a way that does not interfere with the bot's main execution thread. We also need to ensure that queries can access the bot's state and other relevant information.
Another key bit of information is the heterogeneous nature of our bot types. We have realtime and scheduled bots. Realtime bots are always running and can handle queries at any time. Scheduled bots, on the other hand, only run at specific times and may not be running when a query is made. This adds another layer of complexity to query handling.
Oh, and another issue is that this needs to work in both Docker and Kubernetes modes. Very key detail that caused a lot of headaches and "table flipping" moments. Claude and I were in full debate mode for days, throwing small prototypes at each other trying to figure this out. How to make this work and also be maintainable and not a nightmare to deal with in the future. And quite frankly, I'm kinda happy with what we came up with.

So what was the solution? Right, hold tight, it's gonna be a bit of a ride. Firstly, let's do what all software engineers do when faced with a complex problem: We break it down into smaller manageable pieces. Understand how to handle queries for the 2 bot types separately and then figure out how to make it work in both Docker and Kubernetes modes.
For Realtime bots:
- We run a query server as a subprocess on port 9476. This receives a HTTP request.
- On the platform layer, we create a query-server service that has a sole responsibility of resolving global queries (think of it like a gateway). It receives a HTTP request on :9477 and routes it to the appropriate bot's query server based on the bot id. If it's a realtime bot, it does this via a query handler.
- The user's request is thus routed to the bot's query server subprocess which processes the request and returns the result. That's how the magic happens for realtime bots.
For Scheduled bots:
- The query server receives the request on :9477 and checks if the bot is scheduled or realtime.
- If it's scheduled, it spins up an ephemeral container with the bot code and state in query mode.
- The query handler builds the executable container with a
QUERY_PATHandQUERY_PARAMSvariables. - The environment specific component (
docker-runner) starts the container and runs the query entrypoint of the bot. NOTE that here there is no server process running. The ephemeral container just runs the query and exits. It's a terminating program. - The ephemeral container processes the query and stores the results in a temporary section of the object store (minio) and terminates.
- Once the container terminates, the query handler fetches the results from MinIO and returns it to the user.
As you can see there is a tradeoff here. Realtime bots can handle queries with low latency since they are always running. Scheduled bots, on the other hand, have higher latency since they need to spin up a container to process the query. However, this is an acceptable latency of about 1-3 seconds compared to the realtime bots' 10-100 milliseconds. It's an acceptable tradeoff in this case as queries are not mission critical and can tolerate some latency. But that's architecture for ya. Always tradeoffs to be made.
Now for the other elephant in the room. How do we make this work in both Docker and Kubernetes modes?
Here is where knowledge of both domains came in pretty handy. In Docker, we deal with containers, and in K8s, we deal with pods. But at the end of the day, both are just isolated environments that run our bot code. So the core concept remains the same.
In Docker, we have bot-runner and bot-scheduler for realtime and scheduled bots respectively. In K8s, we have bot-controller and schedule-controller for realtime and scheduled bots respectively. The bot-controller just creates a pod with the bot code and state, and the schedule-controller creates a CronJob that creates pods at scheduled intervals. The secret is in how we create these containers/pods.
Query execution in this case is fairly similar.
For realtime bots:
- We have a query-server platform pod that does the absolute same thing as in Docker land. It routes the request to the bot's query server SIDECAR container based on the bot id. So this time when we create a realtime bot pod we add a sidecar container that runs the query server on :9476. This way the query-server platform pod can route requests to the bot's query server sidecar container.
- The sidecar container processes the request and returns the result. Just like in Docker land.
- The main bot container and the sidecar container can share state via shared volumes. This way the sidecar container can access the bot's state and other relevant information. In fact the sync daemon can also run as a sidecar container in this case.
- The rest of the flow remains the same as Docker land.
For scheduled bots:
- The query-server platform pod receives the request and checks if the bot is scheduled or realtime.
- If it's scheduled, it creates an ephemeral pod with the bot code and state in query mode. Just like in Docker land. This pod has a single container that runs the query entrypoint of the bot. We don't need sidecars since we just need to run the query and exit, no state synchronization needed here. So the
schedule-controllercreates a pod with the bot code and state and runs the query entrypoint. - The ephemeral pod processes the query and stores the results in a temporary section of the object store (minio) and terminates. No different from Docker land.
- Once the pod terminates, the query handler fetches the results from MinIO and returns it to the user.
It's literally the same architecture and flow in both Docker and Kubernetes modes. The only difference is in the terminology and how we create the isolated environments (containers vs pods). But at the end of the day, both are just isolated environments that run our bot code. And funny enough, both architectures look pretty much the same:

Docker land:
For simplicity I omitted the fact that the schedule service creates ephemeral containers for scheduled bots. But you get the idea.
k8s land:
Small caveat here for the scheduled pod is that we can't actually use sidecars since it's a terminating pod that just runs the query and exits. So the scheduled pod just has the bot container and a goroutine that runs the sync daemon during the bot's execution. No sidecars needed here.
This way we maintain a consistent architecture and flow across both Docker and Kubernetes modes, ensuring ease of maintenance and scalability and saving on a lot of duplicated code to address the same problem in 2 different ways.
Honestly, this was a proper journey to build even with Claude's heavy hand-holding. The main issue was making sure that the core components of the runtime model do all the resolution legwork. This way we don't have to duplicate code in both Docker and K8s modes to address the same problem and fall into the unmaintainable software trap with lots of awkward edge cases (trust me we still have edge cases here bro). The platform layer components (bot-runner/bot-controller and bot-scheduler/schedule-controller) do all the heavy lifting of creating the isolated environments (containers/pods) with the right configuration (sidecars, env variables, volumes, etc) based on the bot type (realtime/scheduled) and mode (docker/k8s). This way the core runtime components (runtime execute, daemon sync, query server) can remain agnostic of the underlying environment and focus solely on executing the bot code, synchronizing state, and handling queries.
the0 is by no means the best-architected system out there but It fits my needs. On my laptop I run it on Docker mode. On my production servers, I run it on Kubernetes mode. It's flexible enough to adapt to different environments while maintaining a consistent architecture and flow.
This actually wasn't the really hard part. The really hard part was making sure all SDKs had the same capabilities and interfaces for defining state and queries.
I Got 99 Problems, but State Ain't One
With the architecture in place, the next challenge was to ensure that all 7 SDKs (Python, JS/TS, Rust, C#, C++, Scala, Haskell) had consistent interfaces and capabilities for defining state and queries. This was crucial to provide a seamless developer experience across different programming languages. Not gonna lie, my proficiency in some of these languages is pretty meh (looking at you Haskell and Rust), so I had to rely heavily on Claude Opus 4.5 for this part.
Stating Facts
State wasn't really that bad since it's mostly file IO, to be honest. Programmers can just plop a file in the state directory and the daemon will take care of the synchronization. However, we definitely need some form of convenience methods for the most primitive data structures like strings, integers, objects (dictionaries/maps), and lists/arrays. This way developers can easily store and retrieve state without dealing with file IO directly. For example, I want to store the last short window and long window moving averages for my trading bot. Instead of dealing with file IO directly I can just use a convenience method like state.set("short_window", 20) and state.get("long_window"). This way the SDK handles the serialization and storage of the state for me.
Me and Claude did some thinking and came up with some basic convenience methods that can be implemented across all SDKs. We came up with the following:
Loading...
And there we have it, folks. We have consistent state management interfaces across all SDKs. Developers can easily store and retrieve state using simple convenience methods without worrying about the underlying file IO or serialization details. This greatly simplifies the development process and enhances the overall developer experience when working with state in the0. Imagine having to fight with file IO and serialization in every SDK. No thanks, bro. Again this is convenience methods. Developers can still use file IO directly if they want to store complex data structures or files as state. Special the0 state dictionary/map objects are handled in a special section of the state directory so you don't corrupt them just don't delete the /state/.the0-state folder bro.
Queries
Queries were a bit more tricky since they need to provide a customizable request/response interface. Developers need to be able to define their own query endpoints and handle requests in a way that makes sense for their specific bot logic. Basically we need to provide a mini web framework that can be a framework in one case (realtime bots) and a function handler in another case (scheduled bots). For brevity I'll only give you 1 route example per SDK. The rest of the routes can be defined in a similar manner.
Loading...
With these interfaces in place, developers can easily define custom query endpoints that suit their bot's specific logic and requirements. The query framework handles the underlying HTTP request/response mechanics, allowing developers to focus on implementing their bot's unique functionality.
Internally in the SDKs we need to figure out how we can make it go server mode and function mode. Here we can actually use the environment as a context. Since on the platform layer we set environment variables for the containers, we effectively use the environment variables as arguments to determine the mode of operation. If QUERY_PATH is set, we run in query mode. If not, we run in server mode. The platform code really is just setting env vars based on the bot type and the current mode of execution (Docker/K8s).
the0 is open source so you can dig into the actual implementations yourself:
- Node.js SDK: query.ts — the simplest implementation to understand
- Rust SDK: query.rs — if you're feeling brave
The core concept across all SDKs is the same: a run function detects the mode of operation based on environment variables. If QUERY_PATH is set, we run in ephemeral mode. If BOT_TYPE is realtime, we run in server mode. Otherwise, we print available handlers. The handler function registers query handlers, and the mode-specific functions handle the rest.
If you are a Rust, Haskell, Scala or C++ developer who wants to contribute better implementations, hit me up. I'll gladly accept PRs to improve the code quality and maintainability of those SDKs. Honestly, I'm not the best coder in those languages, Claude is way better than me in all of them combined.
Conclusion
Handling state and queries in a multi-environment, multi-bot-type system like the0 while testing multiple SDKs was tough even with Claude's help. But by breaking down the problem into manageable pieces and leveraging subprocesses, sidecar containers, and environment-based mode detection, we were able to build a robust and flexible architecture that meets our needs. The key takeaways from this journey are:
- You still need to think about architecture even with a cracked coder like Claude holding your hand.
- Always think about execution locality; it should tell you where things are really supposed to be.
- Tradeoffs are inevitable in software architecture. Embrace them and make informed decisions based on your specific use case.
- Consistency across SDKs is crucial for a seamless developer experience. Invest time in designing common interfaces and patterns.
- Use all three frontier models to locally review your code! Claude is OP but GPT-5.2 managed to catch quite a few interesting gremlins mainly around TOCTOU race conditions (AWS know this all to well with the US-EAST-1 DynamoDB DNS kerfuffle). These bugs are hard to catch even for experienced programmers. GitHub code reviews fall short when it comes to large PRs. I really think we need better tools for the reams of code that AI generates. Maybe I'll build one in the future, who knows (open source of course).
- I still think of myself as a programmer, even with AI doing heavy lifting. What's changed is scale, not substance. I still had to understand the problem, map out context boundaries, identify edge cases, and guide Claude toward code that fits. AI is a force multiplier, not a replacement. The programmers who thrive will be the ones who learn to wield it—not the ones who fear it.
What's next? First, a drink. Then:
- Dashboards for aggregated bot data — comparative performance views across bots so I know what to scale and what to sunset
- Log search — because debugging shouldn't require grep gymnastics
- Learning Rust properly — Claude's better than me at it, but that's not an excuse to stay ignorant
- Refactoring toward deeper insight — this is probably the 4th major runtime refactor. There will be more. Good architecture is discovered, not designed.
If you're building trading bots or just want to see how the sausage is made, check out the0. And if you're a Rust, Haskell, or C++ dev who wants to contribute better SDK implementations—hit me up. I'll buy you a coffee.