Simplifying the Runtime: What We Learned Deleting 2,200 Lines of Code
We replaced a master-worker architecture with two simple Go services. Here's what we learned about complexity and knowing when "good enough" actually is.
January 2, 2025
TL;DR: We replaced a master-worker architecture with two simple Go services. Here's what we learned about complexity and knowing when "good enough" actually is.
The Setup
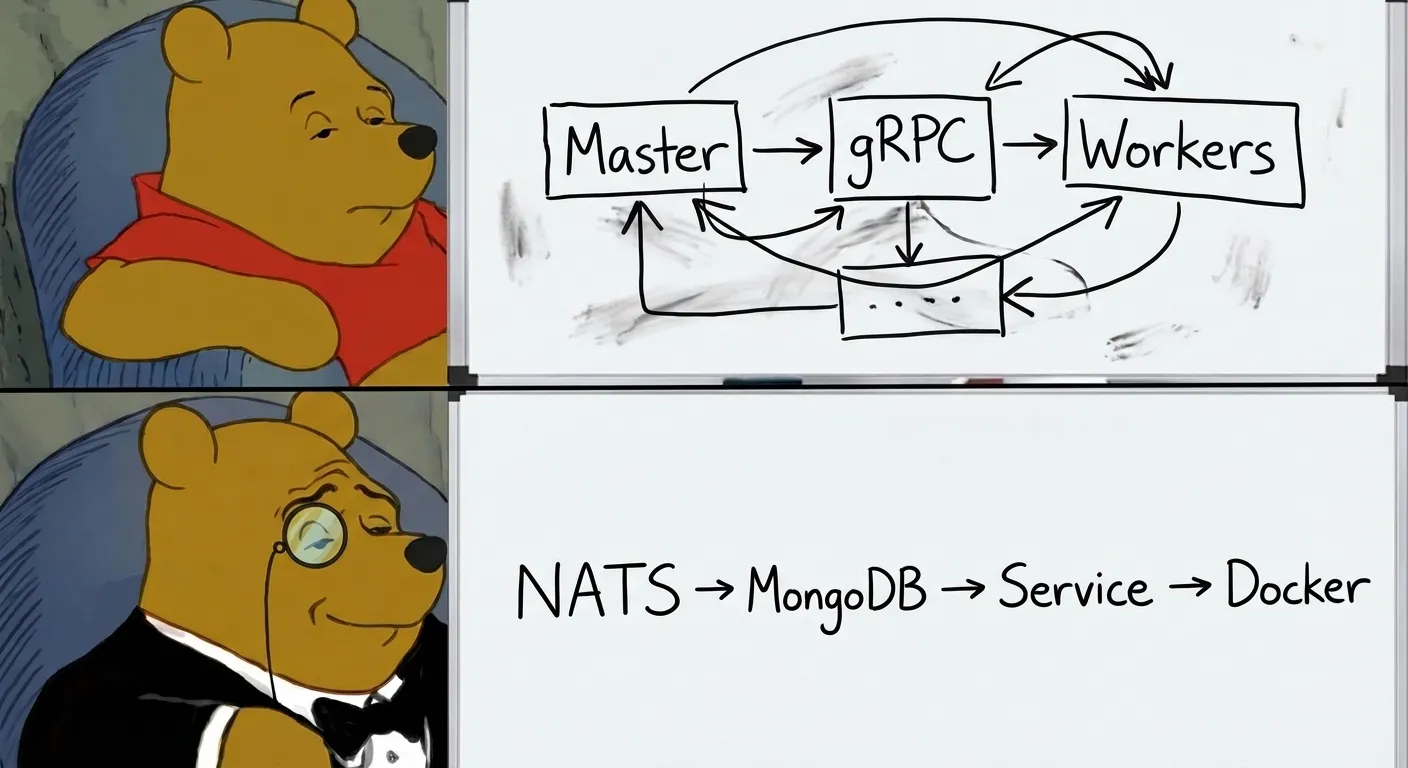
When I first built the runtime, I designed it for scale. Master processes coordinating workers via gRPC. Heartbeat monitoring. Segment-based partitioning. Automatic rebalancing. The works.
It looked like this:
Total: 10 containers (2 masters + 8 workers)
About 2,000 lines of coordination infrastructure. And it worked. But after a few months of maintaining it, I started asking uncomfortable questions.
The Questions
How many bots are we actually running locally? Usually 10-50 during development. Sometimes 100 for stress testing.
What about production? A single trader typically runs a few dozen bots—probably less than 100. A prop trading firm with multiple traders might run 200-500 bots total. A hedge fund might push toward 500-1,000. But by that point, you're running Kubernetes anyway.
Docker's networking can struggle with hundreds of containers on a single network. Most production deployments run 10-50 containers per host before considering orchestration.
So does the master-worker pattern actually help at this scale? No. The coordination overhead was pure cost with no benefit. The architecture was solving problems we didn't have.

The Journey
This wasn't a single PR. It was a three-part refactoring over two days. A substantial change to the runtime, so here's the full story.
Part 1: Consolidation & Shared Modules
First, we cleaned up duplicated code between Docker and Kubernetes modes. The directory structure was a mess—bot-runner/ and bot-scheduler/ were confusingly separate from docker-runner/, which was itself an outdated name. Code was scattered everywhere.
# Before: Code scattered across confusingly named directories
internal/
├── bot-runner/ # Confusingly separate
├── bot-scheduler/ # From docker/
├── docker-runner/ # Old name
└── k8s/
# After: Organized by deployment mode
internal/
├── docker/ # All Docker-mode code
│ ├── bot-runner/
│ └── bot-scheduler/
├── k8s/ # All K8s-mode code
├── model/ # Shared models
├── runtime/ # Shared config (images, resources)
└── entrypoints/ # Shared script generationThe key insight was extracting shared modules that both deployment modes could use. The model/ package now holds Bot, BotSchedule, and Executable structs. The runtime/ package maps language runtimes to Docker images and defines resource limits. The entrypoints/ package generates startup scripts for each language. And util/ handles cron parsing, retry logic, and logging.
Both modes now share the same source of truth. When someone asks "what image does Python 3.11 use?" or "what are the default memory limits?", there's exactly one place to look.
Part 2: Security & Bug Fixes
While consolidating, we fixed issues that had accumulated. On the security side, we added shell injection prevention with regex validation for entrypoints, and pinned Docker images to specific versions—rust:latest became rust:1.83-slim.
We also caught some bugs. A typo (ENTRYPPOINT_TYPE instead of ENTRYPOINT_TYPE) had gone unnoticed for months. The code manager had a file handle leak. And our entrypoint scripts assumed /bin/bash exists, which broke on Alpine images that only have /bin/sh.
Part 3: The Simplification
Then came the big change. We deleted the entire master-worker architecture.
The internal/core/ directory—about 900 lines of master-worker infrastructure—gone. The bot-runner/server/ and bot-scheduler/server/ directories, another 800 lines of worker and master wrappers—gone. The pb/worker.proto gRPC definitions and generated code, roughly 550 lines—gone.
Total: ~2,200 lines deleted.
The New Design
The replacement is straightforward:
Total: 2 service containers
One process queries MongoDB for enabled bots, lists running containers, and reconciles the difference every 30 seconds:
desiredBots := getBotsFromMongoDB()
runningContainers := getContainersFromDocker()
for _, bot := range desiredBots {
if !isRunning(bot) { startContainer(bot) }
}
for _, container := range runningContainers {
if !shouldBeRunning(container) { stopContainer(container) }
}If NATS is available, updates happen instantly. If not, the system falls back to polling. The CLI went from two commands to one:
# Before: Start master, then workers separately
./runtime bot-runner master --mongo-uri ... --address :50051
./runtime bot-runner worker --mongo-uri ... --master-address :50051
# After: Single command
./runtime bot-runner --mongo-uri ... --nats-url ...The Results
| Metric | Before | After |
|---|---|---|
| Containers | 10 | 2 |
| Lines of code | ~4,500 | ~2,300 |
| gRPC definitions | 50 lines | 0 |
| Startup time | Slower (master discovery) | Faster |
| Debugging | "Which worker has this bot?" | "Check the logs" |
The Kubernetes Controller
While we simplified Docker mode, we also built out Kubernetes mode properly. The K8s controller uses the same reconciliation pattern but creates native Kubernetes resources:
We made a few deliberate design choices. MongoDB remains the source of truth—no Kubernetes CRDs, same schema as Docker mode. The existing NATS subscriber writes to MongoDB unchanged. The reconciliation loop compares desired state (MongoDB) against actual state (Pods). And there's a single controller with no segments or partitioning, because Kubernetes already handles scheduling.
The controller creates actual K8s Pods for live bots and CronJobs for scheduled bots. Kubernetes handles health checks, restarts, and resource limits. We stopped trying to reinvent what the platform already provides.

When to Use Each Mode
Docker mode is for development and single-host production. You run docker compose up and you're done. Simple.
Kubernetes mode is for multi-node clusters and high availability. You run kubectl apply and let Kubernetes handle scheduling, health, and scaling. More to set up, but K8s does the heavy lifting.
We stopped trying to make one architecture serve both use cases.
What We Learned
Complexity has maintenance cost. Every abstraction layer is code someone has to understand, test, and debug. The master-worker setup worked, but it was expensive to maintain relative to what it provided.
Consolidate before you simplify. The cleanup in Parts 1 and 2 made the simplification in Part 3 possible. Trying to delete the master-worker code while it was scattered across multiple directories would have been a nightmare.
Shared modules pay off. Extracting model/, runtime/, and entrypoints/ packages meant both Docker and K8s modes stay in sync automatically. When we add a new language runtime, both modes get it.
"Good enough" is underrated. The reconciliation loop isn't clever. It polls every 30 seconds, compares two lists, and syncs them. It's boring, predictable, and easy to debug. That's a feature.
Design for actual usage, not theoretical scale. We built for thousands of bots when we needed dozens. The simpler design handles our actual workload with room to spare.

What's Next
With the runtime simplified, we can focus on what matters. Bots that remember things between runs. Ways to ask your bots questions while they're running. Better visibility into what's happening across your fleet.
The v1.2.0 release is available now. Migration from v1.1.x is simple—the new services are drop-in replacements.
the0 is an open-source algorithmic trading platform. Source code at github.com/alexanderwanyoike/the0.